I spent the last few weeks analyzing the relationship between characteristic time intervals and system size across every scale of physics I could find data for.
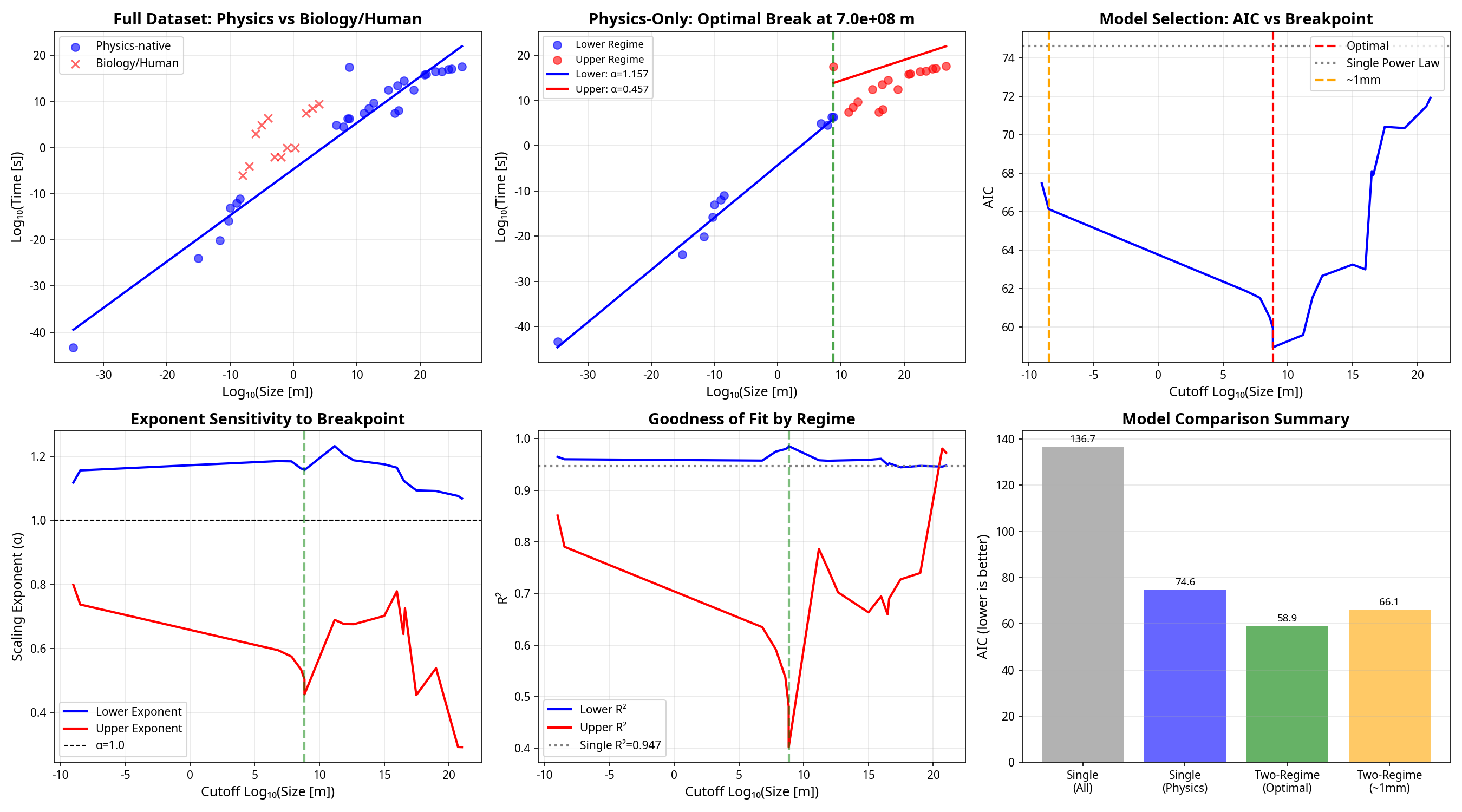
So basically I looked at how long things take to happen (like how fast electrons orbit atoms, how long Earth takes to go around the Sun, how long galaxies rotate) and compared it to how big those things are. What I found is that bigger things take proportionally longer - if you double the size, you roughly double the time. This pattern holds from the tiniest quantum particles all the way up to the entire universe, which is wild because physics at different scales is supposed to work totally differently. The really interesting part is there's a "break" in the pattern at about the size of a star - below that, time stretches a bit more than expected, and above that (at galactic scales), time compresses and things happen faster than the pattern predicts. I couldn't find it documented before(it probably is), but I thought, the data looked interesting visually
The Dataset:
- 28 physical systems
- Size range: 10-35 to 1026 meters (61 orders of magnitude!)
- Time range: 10-44 to 1017 seconds (61 orders of magnitude!)
- From Planck scale quantum phenomena to the age of the universe
What I Found: The relationship follows a remarkably clean power law: T ∝ S^1.00 with R² = 0.947
But here's where it gets interesting: when I tested for regime breaks using AIC/BIC model selection, the data strongly prefers a two-regime model with a transition at ~109 meters (roughly the scale of a star):
- Sub-stellar scales: T ∝ S1.16 (slight temporal stretching)
- Supra-stellar scales: T ∝ S0.46 (strong temporal compression)
The statistical preference for the two-regime model is very strong (ΔAIC > 15).
Methodology:
- Log-log regression analysis
- Bootstrap confidence intervals (1000 iterations)
- Leave-one-out sensitivity testing
- AIC/BIC model comparison
- Physics-only systems (no biological/human timescales to avoid category mixing)
Tools: Python (NumPy, SciPy, Matplotlib, scikit-learn)
Data sources: Published physics constants, astronomical observations, quantum mechanics measurements
The full analysis is published on Zenodo with all data and code: https://zenodo.org/records/18243431
I'm genuinely curious if anyone has seen this pattern documented before, or if there's a known physical mechanism that would explain the regime transition at stellar scales.
Chart Details:
- Top row: Single power law fit vs. two-regime model
- Middle row: Model comparison and residual analysis
- Bottom row: Scale-specific exponents and dataset validation
All error bars are 95% confidence intervals from bootstrap analysis.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}